题目链接:https://github.com/Show-Me-the-Code/show-me-the-code
代码github链接:https://github.com/wjsaya/python_spider_learn/tree/master/python_daily
个人博客地址:https://wjsaya.github.io
第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接 里的日本妹子图片 :-)
思路:
- 加载帖子url
- 解析返回的网页结构,获取所有图片的id
- 根据图片id下载对应的预览图和大图
- 下载的预览图存放路径为./pic/XXX.jpg
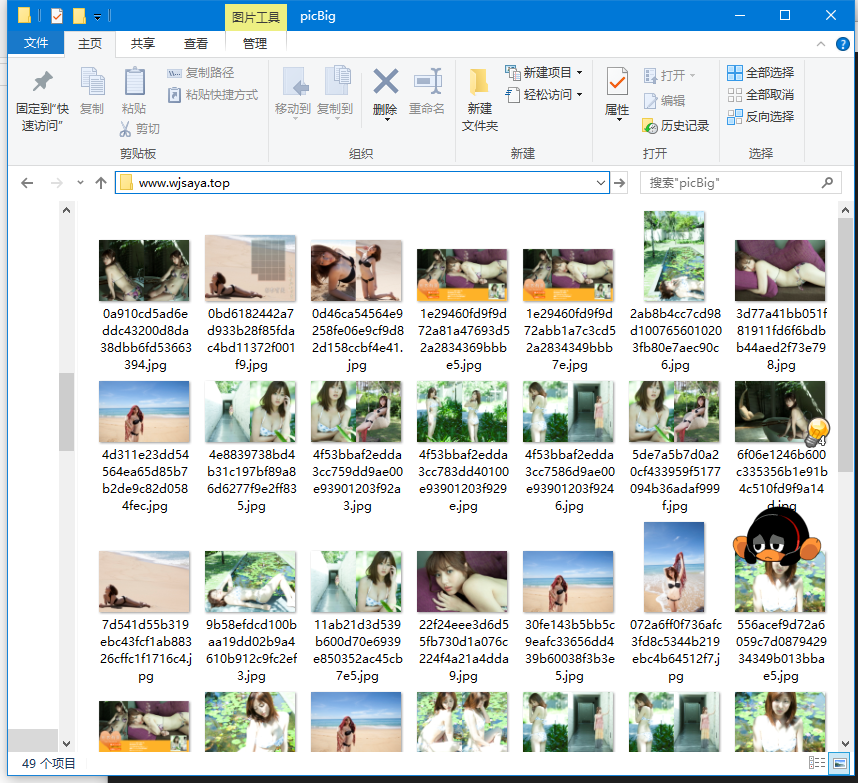
- 大图路径为./picBig/XXX.jpg
代码:
|
|
效果图:
总结:
爬虫自己写过一些了,这个题目的需求还是比较简单的。只是简单的获取一下网页上的图片而已,不需要解析网页加载过程。前段时间把贴吧的自动签到功能实现了,后续还实现了模拟手机app签到以获得双倍经验。有空了把那份代码整理整理发出来。。。