题目链接:https://github.com/Show-Me-the-Code/show-me-the-code
代码github链接:https://github.com/wjsaya/python_spider_learn/tree/master/python_daily
个人博客地址:https://wjsaya.github.io
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 替换,例如当用户输入「北京是个好城市」,则变成「*是个好城市」。
思路:
- 从文件解析敏感词、从终端获取用户输入。
- 根据敏感词对用户输入进行过滤。这里过滤需要考虑到输入内容不止一个需要过滤的词,所以稍微麻烦点:
- 读取所有的屏蔽词,放进一个列表
- 获取用户输入
- 遍历屏蔽词列表,用屏蔽词检索用户输入
- 如果有屏蔽词,将其替换为*
- 如果没有,不进行操作
- 返回处理后的用户输入
- 用下一个屏蔽词对处理后的用户输入进行上述操作
- 所有屏蔽词遍历完毕,输出过滤后字符串
敏感词列表(filtered_words.txt)
|
|
代码:
|
|
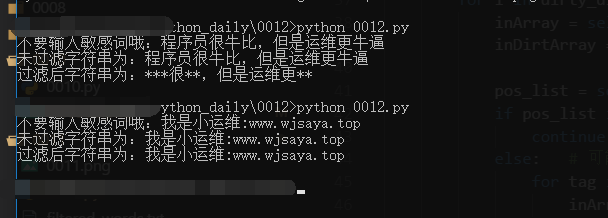
效果图: