题目链接:https://github.com/Show-Me-the-Code/show-me-the-code
我的github链接:https://github.com/wjsaya/python_spider_learn/tree/master/python_daily
个人博客地址:https://wjsaya.github.io
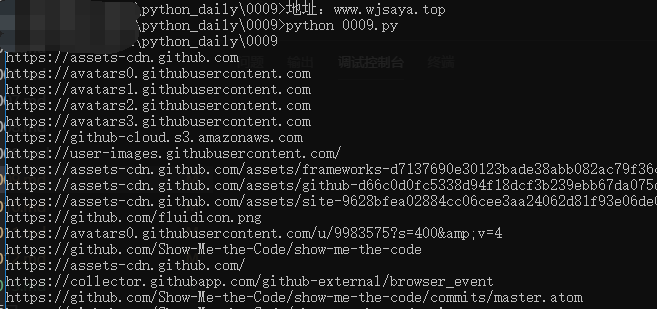
第 0009 题:一个HTML文件,找出里面的链接。
思路:
- 打开html文件;
- 逐行读取文件;
- 通过正则表达式匹配http://之类的开头的链接即可。
代码:
|
|
效果图: