最近在学习python爬虫,写出来的一些爬虫记录在csdn博客里,同时备份一个放在了github上。
github地址:https://github.com/wjsaya/python_spider_learn/
本次内容:从煎蛋网下载图片
思路:
- 拼接出所需的页面URL。
- 用BS去访问和解析页面URL,获取页面内的所需图片并保存到本地并重命名。
代码:
|
|
下载过程截图: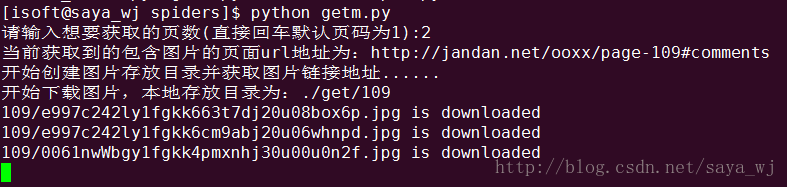
恩。。。效果图: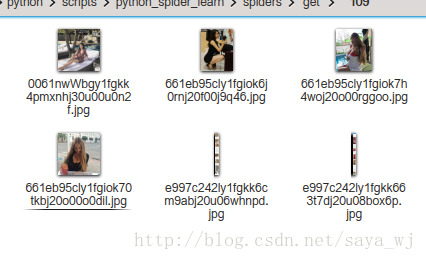
最近在学习python爬虫,写出来的一些爬虫记录在csdn博客里,同时备份一个放在了github上。
github地址:https://github.com/wjsaya/python_spider_learn/
本次内容:从煎蛋网下载图片
|
|
下载过程截图:
恩。。。效果图: